
The insurance industry is undergoing significant changes due to the emergence of new risks, advancements in technology, availability of external data, and shifts in consumer preferences. This presents opportunities for insurers to use data and insights to improve operations, personalize products and services, and compete in new ways. To stay competitive, insurers must move quickly to drive AI-driven innovation and improvements while addressing these risks. One way to do this is to focus on DataOps and MLops, popularly known as XOps, which is the ability to iterate quickly and effectively across the entire lifecycle of algorithmic models. This allows insurers to track their progress and become a more data-driven business.
However, scaling data science to achieve these rewards takes time. Successful insurance companies have built an excellent analytical process to create a steady flow of models to tap into this new opportunity. However, getting it wrong can lead to spiraling operational expenses, significant financial and reputational risks, and creating wrong models or misuse.
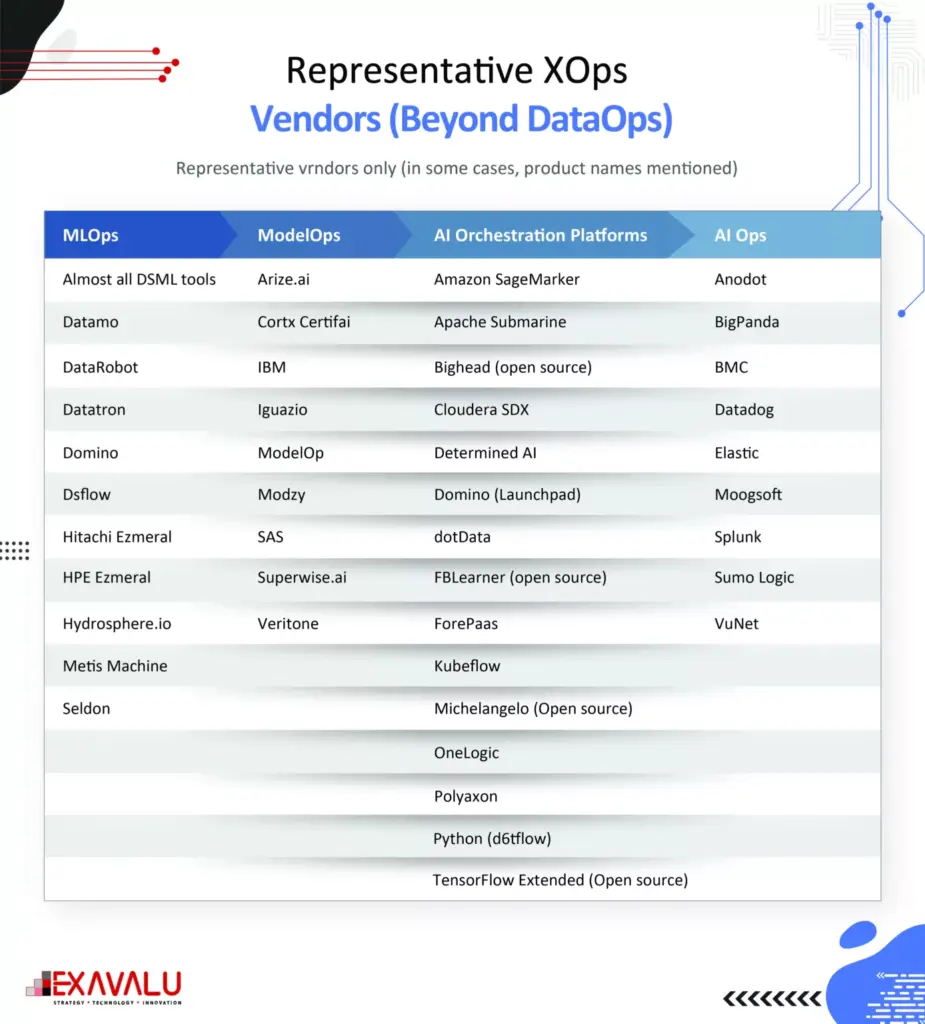
Successful companies have a holistic approach to increasing efficiency throughout the data science lifecycle. This approach is called Enterprise XOps/MLops, which is a combination of technologies and best practices that streamline the management, development, deployment, and monitoring of data science models at scale across an enterprise. This paper will discuss the challenges of scaling data science and will explain how a poorly defined approach can lead to obstacles and how Enterprise MLops can overcome this challenge.
Scaling Machine Learning is Difficult
Companies leveraging the XOps (DataOps, ModelOps and MLOps) have high expectations from their data science teams, with 25% expecting outcomes that increase revenue by 11% or more. Gartner predicts that by end of 2024, 75% of organizations will shift from piloting to operationalizing their AI usage, driving a 400% increase in streaming data and analytics infrastructures. However, despite large investments, results have not been as successful as expected. Additionally, a significant number of companies plan to scale data science capabilities within the next five years leading to the increased importance of an enterprise MLOps approach that avoids building operational silos. To overcome these obstacles, companies can apply the technical principles of MLOps to the entire data science lifecycle and consider how to apply these efficiencies to processes and people.
Entry Barriers to Scale for Models
Advancements in the last decade in using AI and Models in insurance have focused on building models with little focus on operationalizing machine learning model development at the enterprise using advanced infrastructure management and Dev/Ops automation. There have been many barriers, including analysts and data scientists waiting for data from data engineers, code refactoring for production, fixing data quality issues when developing models, retraining ML models with new training data, waiting for testing to be completed, provisioning environments for analytical workloads, packaging dev outputs for production and fixing outages due to excessive load. It is easier for platforms to solve scaling problems in the back-end production of the data science lifecycle rather than the research and development in the front end. In the back end, the model is already built and packaged as a file, supported by a data pipeline, and often wrapped in a container.
How Enterprise MLOps Scales Data Science
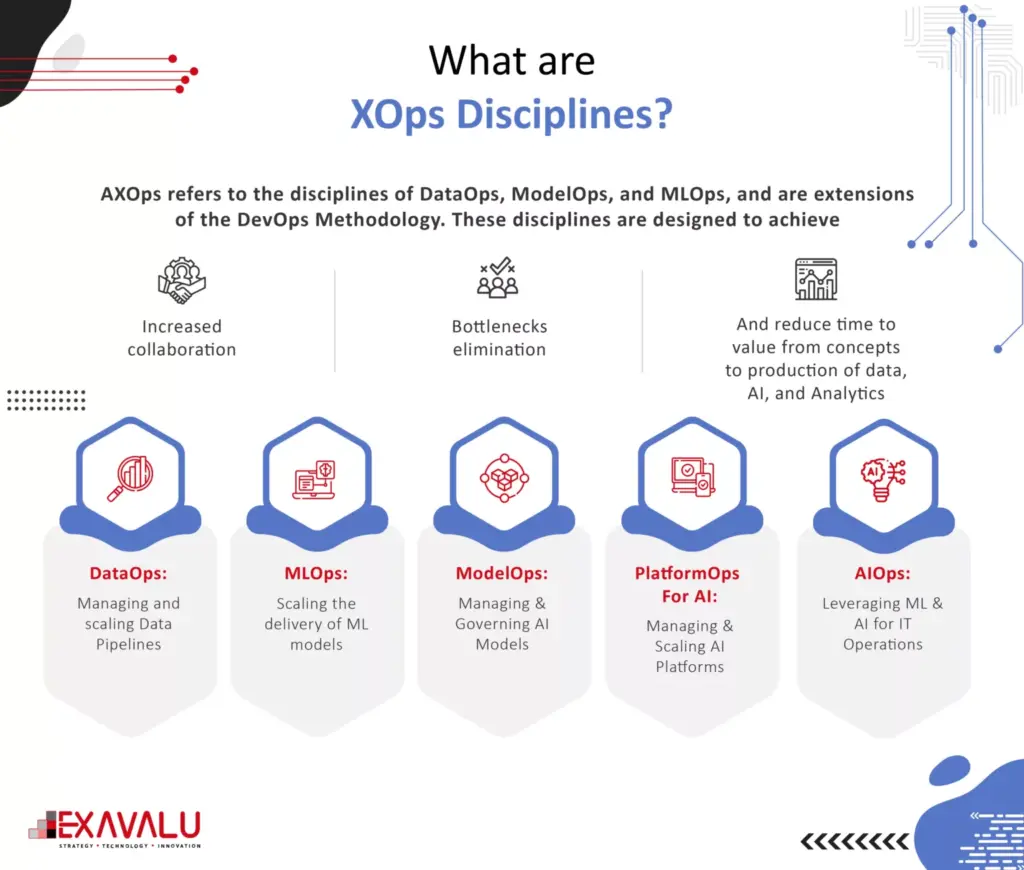
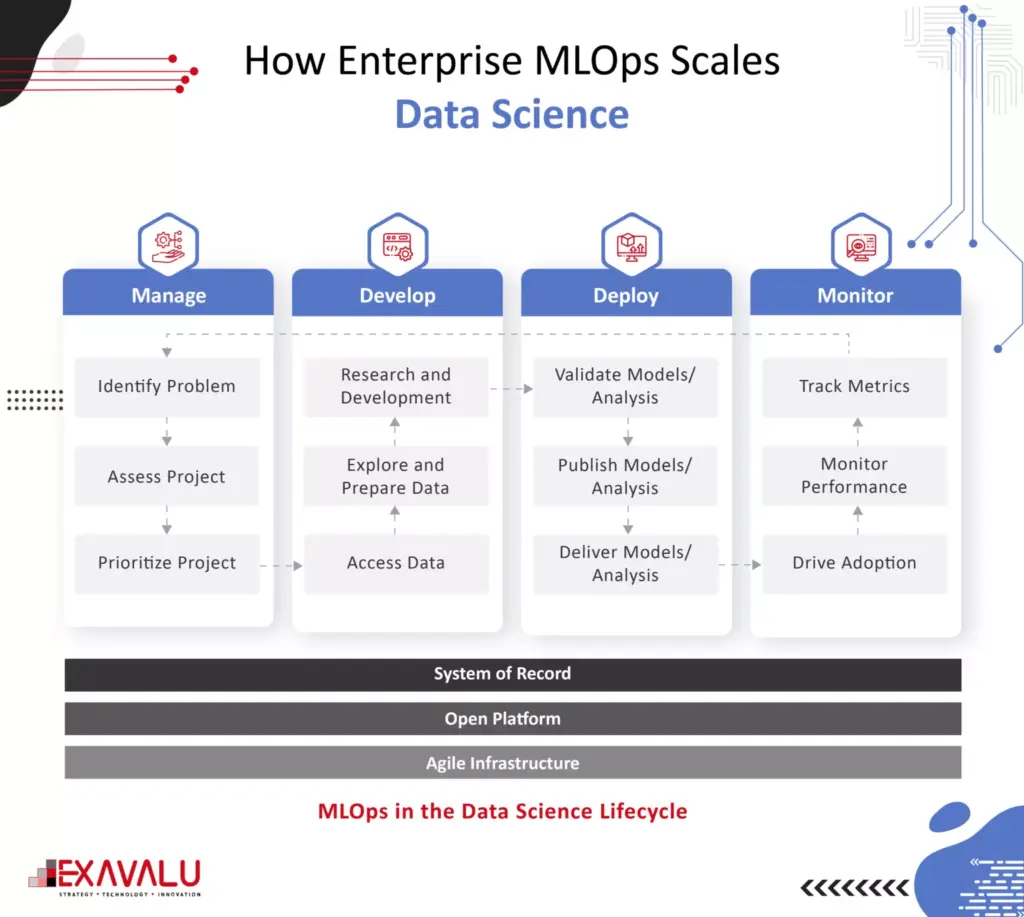
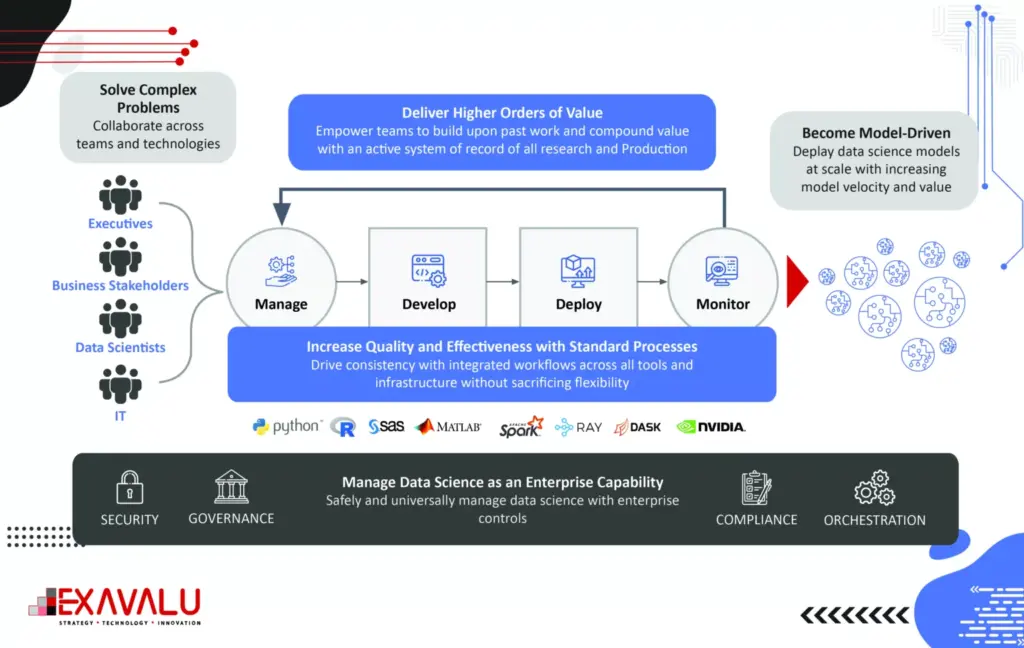
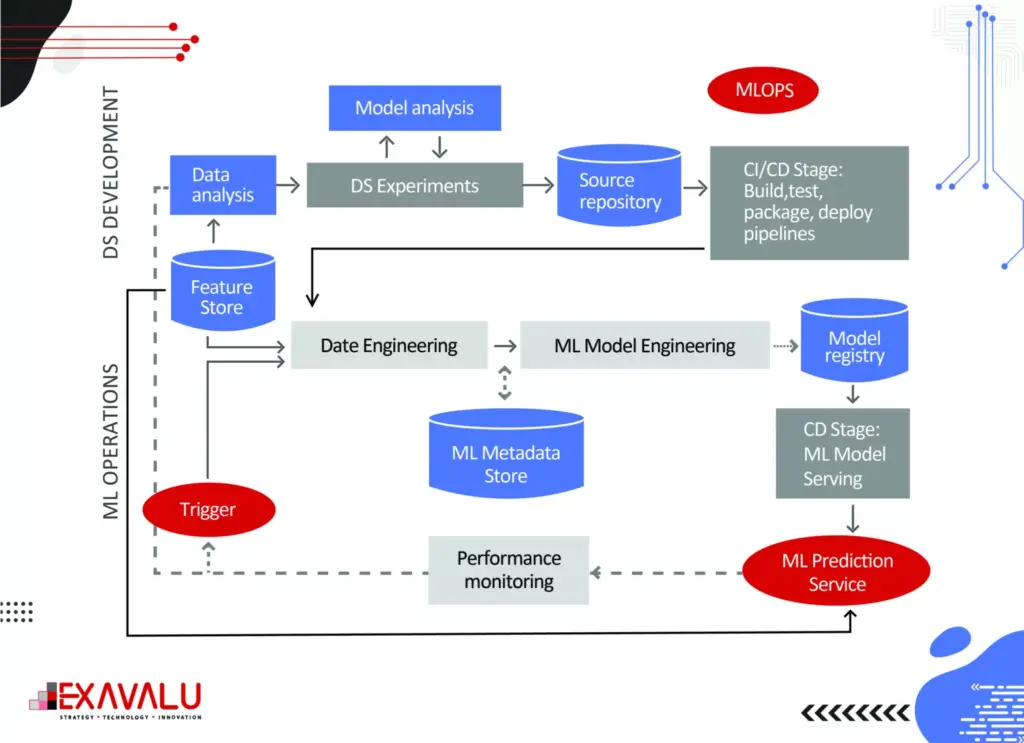
The core capabilities of an Enterprise MLOps platform provide a comprehensive approach for scaling data science for model-driven companies. Such an approach must address data access, model validation, model automation, and monitoring gaps. Enterprises must build models, test, deploy and monitor in a continuous cycle that integrates machine learning, software development, and IT release management and deployment. These capabilities cover four phases of the entire data science lifecycle: manage, develop, deploy, and monitor business outcomes. By providing capabilities for the entire lifecycle, a model-driven business can avoid common mistakes and issues arising from a more limited definition of MLOps. MLOps can operationalize data science at scale.
A mitigation plan involves collaborative working in a single team, developing coding standards and best practices, creating metrics and processes around that, using model registries and version control to rerun pipelines, enabling a dynamic sandbox environment utilizing cloud services, and building a continuous deployment pipeline.
Mlops Capabilities that Organization should bring about
Managing the Data Science Lifecycle is the first phase of the data science lifecycle. A significant objective of this phase is breaking down knowledge silos that keep data scientists from collaborating. Because data scientists often work independently with various tools, there are no standard ways of working, compromising governance, auditability, reproducibility, etc. Apart from creating feature Store solutions, Model development tools, CI/CD and code repository, ML compute engines, workflow and model orchestration, Data model and experiment tools, deployment tools, and monitoring tools are important for a carrier from a capability standpoint. For example, Feature Stores make the data scientist’s work more convenient & efficient by abstracting much of the engineering work required to acquire, transform, store, and use features in ML training and inference. Strong project management capabilities are also essential for scalability in this phase. The managing stage will enable control and collaboration of large stakeholders and facilitate audit and review processes.
Developing Models for Business Use Cases
In the Development phase of the data science lifecycle, access to the right tools and infrastructure is essential for data scientists to be productive and innovative. When data science teams cannot access the necessary resources, they may create ad-hoc workarounds that involve building and maintaining their local infrastructure, leading to inefficiencies, frustration, and increased operational and security risks. Complex problems arise when sourcing and blending raw, structured, and external/cloud data at scale. Additional complexity arises from inadequate model feature stores, model packaging, and validation capabilities. A new data orchestration approach is available to accelerate the end-to-end ML pipeline. Data orchestration technologies abstract data access across storage systems, virtualize all the data and present the data via standardized APIs and a global namespace to data-driven applications. Data orchestration can already integrate with storage systems; machine learning frameworks only need to interact with a single data orchestration platform to access data from any connected storage. As a result, training can be done on all data from any source, leading to improved model quality. There is no need to move data to a central source manually. All computation frameworks, including Spark, Presto, PyTorch, and TensorFlow, can access the data without concern for where it reside. Key benefits of the platform included shared resources, elimination of silos, centralized access to data for better governance and security, and centralized and shareable environment management, enabling the company to operationalize data science at scale across the organization.
Deploying Models for Production
The Deploy phase is critical for operationalizing models at scale and is traditionally where the highest value is achieved from MLOps. However, many organizations still need help with the model deployment process, which can be time-consuming and require close oversight from IT support staff. An Enterprise MLOps platform can streamline the deployment and change management processes, allowing data scientists to deploy models independently without relying on IT or software developers. This can save time and add value to the business. Given the high levels of AI failure rates, companies need a structured way to manage their models for successful ML applications. Model registry, a tool designed to manage models systematically. A model registry makes collective action easier. Thanks to its centralized storage, the most up-to-date version of all models can be found. Thus, data scientists can avoid the risk of working on overlapping problems or falling into the same mistakes. Being informed of others’ actions both enable joint work and save time. A model registry makes the lifecycle of models transparent. This way, each team member can keep track of a model’s progress. A model registry facilitates model deployment in which models are pushed into production. Data scientists can streamline by tracking, monitoring, comparing, and searching all the models. A model registry can be confused with experiment tracking. However, even though experiment tracking allows tracking different versions of a model and storing training data, they serve different purposes. This allowed them to efficiently deliver customized models.
Monitoring the Model Portfolio for Ongoing Performance
Monitoring is about keeping track of model performance, ensuring that models continuously learn, continually rebuild (CI/CD), and preventing model drift or even the improper use of models. ML model monitoring platform that can boost the observability of your project and helping you with troubleshooting production AI. Automatic model monitoring should be proactive rather than reactive so that you can identify performance degradation or prediction drifts early on. Automated monitoring systems can help you with that, and integrations with tools like PagerDuty or Slack can notify you in real time. It demands zero setups and provides space for easy-to-customize dashboards. While these objectives may seem obvious, many (if not most) enterprises that fail to scale models in production are falling short in the Monitor phase because they are disengaged with systematically ensuring model performance and business outcomes. Enterprise MLOps needs to integrate a strong model maintenance plan to implement monitoring at scale. The risks of ignoring the monitoring responsibilities pose real consequences from wrong models or their improper use – including significant monetary and brand reputation risks. Model maintenance should make it easy to trace the history of models and quickly reproduce them in follow-up experiments, tuning, and re-validation. They are improving their model monitoring capability. It infuses data science across its operations to provide consumers with a better, faster insurance experience. The company adopted Enterprise MLOps technology and practices to get insights into how models perform in real-time and detect data and model drift once models are in production. The new approach saves us significant time previously spent on maintenance and investigation and enables us to monitor model performance in real time and compare it to our expectations. In one case, they could automatically detect drift that had previously taken three months to identify manually.
Conclusion
In summary, MLOps or Machine Learning Operations is a concept that aims to improve the collaboration and automation of the entire data science lifecycle, from research and development to deployment and maintenance.
However, there is an essential enabling capability on the Dataops side of the house, which is modern tools for batch and streaming data ingestion and also advanced tools for data quality monitoring and tools for data transformation. The traditional definition of MLOps is limited to the back end, focusing on the deployment and maintenance of models. However, a more comprehensive definition of MLOps, known as Enterprise MLOps, applies to the entire data science lifecycle, including the front-end R&D phase and the back-end model creation and management. By addressing the challenges and obstacles in the R&D phase, such as silos, resources, governance, software, security, visibility and lineage, an Enterprise MLOps platform can help organizations to achieve scalability in data science and realize the ROI they hope for the business.




